Editor’s note: Rebecca Lynn is a general partner at Canvas Venture Fund, an early-stage venture capital firm. She has led investments in Lending Club in 2009, Check in 2011 and FutureAdvisor in 2014 and sits on the boards of Lending Club, Check, FutureAdvisor, Doximity, Convo, HealthLoop and Socrata. She also led the Series A investment in Practice Fusion.  Â
Historically, when looking for opportunity in the financial industry where technology can have the greatest impact â€" for investors and entrepreneurs â€" the best place to start has been with one of our oldest institutions: banks. However, while critical to our economy, banks are generally inefficient, have high fixed costs and don’t exactly elicit happy thoughts from the average consumer. It’s for these reasons, among others, that the biggest opportunities in the financial world revolve around the disintermediation of these banks and core financial services.
Given this backdrop, it’s not hard to imagine that a majority of the people in the U.S. could be “banking†with startups, in one form or another, in the next three to five years. It’s been happening for some time, but the pace and volume of business taken away from banks by startups in the last few years have been significant â€" and this trend will continue to grow.
Disintermediation of Consumer Credit
For starters, we have to look no further for evidence of the inefficiency of our banking system than during our most recent recession. In 2009, the credit crisis was at its peak, and it was practically impossible to get a loan, even for prime borrowers. Interest rates were low, with consumers receiving 0.25 percent on a savings account and prime borrowers paying upwards of 18 Â percent annual percentage rate. The spread was huge, and so was the opportunity.
The credit crisis showed the tech industry that one of the biggest areas of opportunity for startups was in re-imagining consumer lending. People were looking to alternative forms of lending for answers and thanks to the problems above, interest in solutions like peer-to-peer lending were on the rise. Not surprisingly, a cohort of companies emerged to take advantage of these trends, beginning with Prosper, which was soon followed by Lending Club and a litany of others.
At the core of this emerging market was the desire to take banks out of the equation and connect investors directly with those in need of capital. In other words, disintermediation. Furthermore, investors looking for options in a down economy wanted stability, transparency, shorter duration and less credit risk, while maintaining solid returns. Compared to traditional options like high-yield bonds, peer-to-peer lending had appeal.
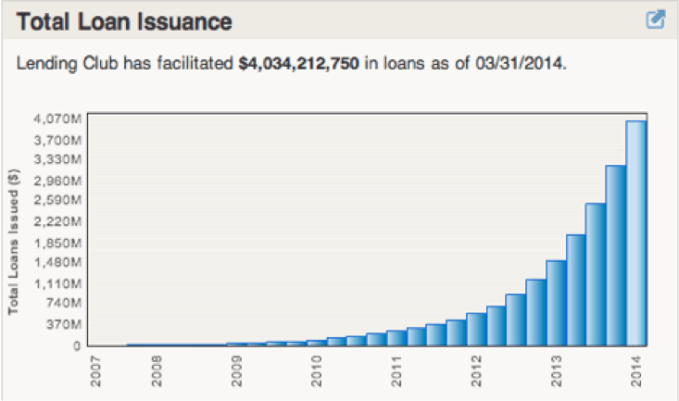
Today, companies like Prosper and Lending Club continue to thrive. Prosper has raised $145 million to date from a host of investors, including Sequoia and DFJ, and projects that it will hit $2 billion in loans originated this year. Lending Club had issued $4 billion in loans by the end of March 2014, and became cash-flow positive in 2012. [Full disclosure: I am an investor in Lending Club.]
Of course, it wasn’t an easy road for either company. Both had to survive significant regulatory scrutiny and approval by the SEC, and investors were understandably wary of newer lending models, like peer-to-peer. As a result, it took Lending Club five years to issue $1 billion in loans (2007-2012), but once it passed regulatory scrutiny and both consumers and investors alike came around, these companies grew quickly. It then took the company only one year to top $2 billion (2013).
By the end of the first quarter, Lending Club had reached $4 billion, and part of the reason that both it and Prosper have continued to see steady growth is that they made peace with taking their time and built measured growth into their DNA. In Lending Club’s case, it took time to set the table â€" to register with the SEC, earn real trust with consumers and lenders, and achieve growth while avoiding sub-prime borrowers. They had to be measured in their growth strategy and each step had to be completed and in place before they could move on to the next.
The other factor that has led to Lending Club’s success and plays into the theme of disintermediation we’ve been seeing over the last five years is that it has looked to differentiate itself from traditional lenders (and other startups) by adopting a model that has been used by many other successful tech companies, like eBay and Amazon, for example.
Few have talked about it, but Lending Club and Prosper’s key differentiator is that they are marketplaces. Most other lenders aren’t. They have to borrow money either by going after warehouse lines of credit or they loan out equity capital. Lending Club and Prosper, however, connect buyers and sellers through peer-to-peer lending marketplaces. And as a result, and this is key, it doesn’t have the same balance sheet risk as other traditional lenders might have.
Mobile and the Disintermediation of Bill Pay, Processing & More
Of course, the opportunities for disruption at the hands of disintermediation extend beyond lending. The smartphone and increasing mobility of our world is changing the game. The consumerization of the enterprise and the “BYOD†(bring your own device) trend within businesses mean that phones and tablets are becoming entrenched features within the corporate and consumer worlds.
Companies like Intuit, eBay/PayPal, Mint.com started the ball rolling when it comes to disintermediation, and today a new generation of companies like Square, Braintree, Dwolla, Simple, Venmo, InDinero and Check are taking it to the next level. But it’s not just startups alone. Consumer brand giants are leveraging both startups and the reach of the new mobile phone network to edge into territory that has traditionally been controlled by banks. Starbucks partnering with Square to be the main processor at thousands of locations is just one of many notable examples.
While banks have traditionally owned the small business space, platforms like Square, Intuit and PayPal â€" and even Amazon and Groupon â€" are playing the “disintermediator†and are putting credit card processing in the hands of SMBs (small and medium businesses) and consumers. Not only that, they’re bundling in other services with processing and targeting them at SMBs.
The growing mobility of the average consumer has allowed businesses to spring up and grow by assuming roles traditionally reserved for banks. Check is one of these businesses trying to do an “end-around†on banks by giving consumers the ability to aggregate and manage all of their critical banking information and bills in one place â€" on their smartphones. [Full disclosure: I am an investor in Check.] Rather than consumers being forced to go to their banks’ websites, their utility company’s website and so on, it put all of these services in one place.
And again, the first generation of financial technology companies (and banks) have taken notice, and one doesn’t have to look far for examples: BBVA acquired Simple in February for $117 million; Braintree acquired Venmo in 2012 for $26 .2 million; PayPal acquired Braintree last September for $800 million; and Intuit acquired Check in May for $360 million.
Disintermediation of the Second Tier
With a loss of faith in the banking system, mobility on the rise and SMBs beginning to take back some control, we’ve also begun to see an increasing number of people not only turning away from traditional banks, but begin to embrace virtual marketplaces. Just as Lending Club and Prosper took advantage of the limited access to banking capital that begin during the Credit Crisis, marketplaces like Kickstarter, Indiegogo, Venmo, Crowdtilt, and Fundly are giving people and businesses an easier way to test, build and fund their products, invest in businesses, pool money, pay friends and facilitate microtransactions. [Full disclosure: My firm is an investor in Fundly.]
Disintermediation is also beginning to seep into other “older†financial services markets, like wealth advisory. Not unlike banks, wealth advisory is an inefficient cottage industry that traditionally comes loaded with fees and a total lack of transparency. Companies like Wealthfront, Betterment, SigFig, FutureAdvisor and more are looking to help consumers minimize fees and maximize returns. [Full disclosure: I am an investor in FutureAdvisor.]
As people start to rely less and less on the institutions that have traditionally acted as sole providers of those services and have maintained a vise-like grip on market share, we’ve begun to see disintermediation arrive in complementary financial services â€" to the second tier, if you will. And if the last five years is any indication, it won’t stop at second-tier services.
What’s Next â€" in the Wake of Bitcoin?
So, as we look forward, at all the possibilities inherent in crowdfunding, microfinance and microlending, we’re seeing new potential for companies to provide the next generation of those payment rail systems â€" the kind for which people have traditionally relied on from banks. As we all know, money transfer is far from instantaneous â€" and even further from being free.
That’s why bitcoin and the latest forms of cryptocurrency are so exciting. Digital currencies like bitcoin have the potential to drive down transaction fees in a big way. Say, for example, you sell electronics or operate a business where profit margins are slim, say under 5 percent. In this case, the traditional 2.5 percent payment fees eat up half of your margins. But with bitcoin, companies could see a significant reduction in transaction fees and, as a result, a boost to their bottom line.
What’s more, many small businesses struggle with accepting international payments, but with a distributed, decentralized digital currency, international borders and monetary systems decrease in importance and relevance. It also could be hugely beneficial for micropayments, especially on mobile platforms, and a digital currency of record could become the micropayment system for the web, allowing publications, for example, to accept fractions of a cent for every article a reader consumes. It opens up a whole new set of monetization options and alternatives to the traditional paywall.
Of course, while the prospect of a digital currency becoming a sort of free rails for moving money is exciting, interchange fees still exist today with bitcoin, and regulation, true anonymity and volatility still remain question marks.
But the world of digital currency remains an exciting area of opportunity. Other areas that are prime for disruption by startups include underwriting and risk scoring; both areas are being reinvented today through the availability and abundance of new data types.
From the rise of peer-to-peer lending models, mobile wallets, digital investment advisory, to the bitcoin revolution, today’s digital disintermediation comes in many forms â€" all of which challenge banks to innovate. To those startups that aim to fundamentally change the way we transact for the better, we’ll be cheering you on.
IMAGE BY Shutterstock USER Christopher Boswell
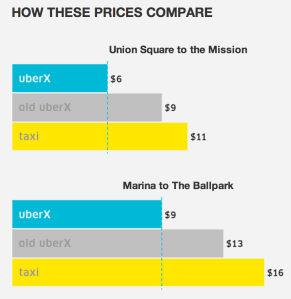 Taxis were already struggling to compete. With inconvenient meatspace hailing, unreliable scheduled pickups, beat-up cars, and unaccountable drivers, many people think the taxis deserve to go the way of the dinosaur. There’s no denying that uberX is great service, and I use it frequently.
Taxis were already struggling to compete. With inconvenient meatspace hailing, unreliable scheduled pickups, beat-up cars, and unaccountable drivers, many people think the taxis deserve to go the way of the dinosaur. There’s no denying that uberX is great service, and I use it frequently.